
در دنیای هوش مصنوعی، کاهش هزینههای پردازشی همیشه یکی از بزرگترین چالشهاست. محققان DeepSeek با معرفی مدل آزمایشی جدید V3.2-exp گامی مهم در این مسیر برداشتهاند. این مدل وعده میدهد عملیات با متنهای طولانی را سریعتر و بهینهتر انجام دهد.
آیا با راهاندازی کانال تلگرام برای انتشار فیلمهای معرفیشده توسط نت باز 360 موافق هستید؟
سیستم Sparse Attention این مدل، با بهرهگیری از تکنیکهای هوشمند انتخاب توکن، توانسته هزینههای پردازش را در برخی سناریوها تا نصف کاهش دهد. این دستاورد بهویژه برای توسعهدهندگان و شرکتهایی که به پردازش متنهای طولانی علاقه دارند، خبر خوشحالکنندهای است.
ویژگیهای کلیدی مدل V3.2-exp که باید بدانید
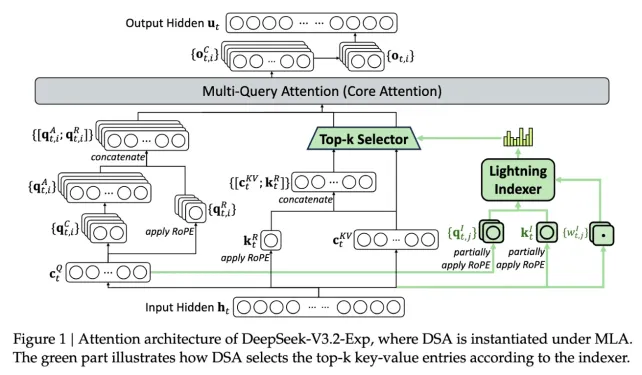
- معرفی سیستم Sparse Attention
DeepSeek Sparse Attention هسته اصلی مدل است. این سیستم با دو زیرمجموعه مهم کار میکند:
- Lightning Indexer: بخشهایی از متن طولانی را اولویتبندی میکند.
- Fine-Grained Token Selection System: توکنهای دقیق و ضروری را از بخشهای منتخب انتخاب میکند.
این ترکیب به مدل اجازه میدهد بدون نیاز به منابع سرور زیاد، عملیات روی متنهای طولانی را با دقت بالا انجام دهد.
- کاهش هزینههای پردازش
آزمایشهای اولیه نشان داده است که هزینه یک تماس ساده API در عملیات طولانی، میتواند تا 50% کاهش یابد. این مزیت برای شرکتها و توسعهدهندگان، کاهش چشمگیر هزینههای پردازشی را به همراه دارد.
- متن باز و قابل دسترس
مدل V3.2-exp به صورت open-weight در Hugging Face منتشر شده است. بنابراین محققان و توسعهدهندگان میتوانند به سرعت تستهای خود را انجام دهند و کارایی مدل را بررسی کنند.
- تاثیر بر بازار هوش مصنوعی
با وجود اینکه این مدل به اندازه مدل R1 جنجال ایجاد نکرد، اما احتمال دارد شرکتهای آمریکایی و دیگر توسعهدهندگان با الگوبرداری از sparse attention model بتوانند هزینههای پردازش خود را به طرز چشمگیری کاهش دهند.
- بهینهسازی معماری ترنسفورمر
DeepSeek با تمرکز بر بهبود معماری پایه ترنسفورمر، نشان داده است که میتوان با تغییرات هوشمندانه، بدون کاهش دقت، مصرف منابع را کاهش داد. این مسئله اهمیت بالایی در بهینهسازی مدلهای بزرگ زبان دارد.
ویژگیهای کلیدی مدل V3.2-exp
|
ویژگی |
توضیح |
| Sparse Attention |
سیستم انتخاب توکن هوشمند برای متن طولانی |
|
Lightning Indexer |
اولویتبندی بخشهای مهم متن |
| Fine-Grained Token Selection |
انتخاب دقیق توکنها از بخشهای منتخب |
|
کاهش هزینه API |
تا 50% کاهش هزینه در عملیات طولانی |
| متن باز |
دسترسی آزاد در Hugging Face برای تست و توسعه |
مدل جدید DeepSeek میتواند الگویی برای کاهش هزینههای پردازش مدلهای بزرگ زبان باشد. با توجه به محدودیتهای منابع سرور در سرویسدهی مدلهای AI، تکنیک Sparse Attention میتواند به شرکتها امکان دهد پردازش متن طولانی را مقرون به صرفهتر انجام دهند. در آینده، انتظار میرود این رویکرد نه تنها در کاهش هزینه، بلکه در بهبود سرعت و مقیاسپذیری مدلها نیز تاثیرگذار باشد. همچنین، با انتشار متن باز، بررسیهای مستقل کارایی مدل توسط جامعه علمی، اعتبار و کاربرد آن را بیشتر میکند.
جمعبندی
مدل V3.2-exp از DeepSeek با سیستم Sparse Attention، کاهش چشمگیر هزینههای پردازش متنهای طولانی و بهینهسازی معماری ترنسفورمر را ممکن کرده است. دسترسی متن باز به این مدل فرصت تست و توسعه آن را برای جامعه تحقیقاتی و شرکتها فراهم میکند و میتواند الگویی برای بهبود کارایی مدلهای بزرگ زبان در آینده باشد.
FAQ
- Sparse Attention چیست؟
یک سیستم هوشمند انتخاب توکن است که متن طولانی را به بخشهای مهم تقسیم و توکنهای ضروری را پردازش میکند. - مدل V3.2-exp چه مزیتی دارد؟
کاهش هزینههای پردازشی تا 50% در عملیات طولانی، دسترسی متن باز و بهبود عملکرد مدلهای بزرگ زبان. - دسترسی به مدل چگونه است؟
این مدل به صورت open-weight در Hugging Face منتشر شده و برای توسعهدهندگان قابل استفاده است. - آیا این مدل جایگزین R1 خواهد شد؟
خیر، این مدل بیشتر بهینهسازی پردازش متن طولانی را هدف قرار داده و جنجال R1 را ندارد، اما میتواند الگویی برای کاهش هزینهها باشد. - کاربرد اصلی مدل Sparse Attention کجاست؟
پردازش متن طولانی در اپلیکیشنهای NLP، هوش مصنوعی و تحلیل دادههای بزرگ با هزینه کمتر.




















